ATS
Recruitee, Greenhouse, Workday
Screening evaluations mirrored back into the candidate pipeline. The recruiter reads the evidence and decides, without leaving the tool they already use.
The platform
Who to hire, who to promote, who to move. You keep the decision. Underneath sit two intelligence engines, agents grounded in real data, and a knowledge graph that sharpens with every project. So the evidence behind your call is deterministic, traceable, and explainable.
What the core is
The hard part of a people decision is the evidence: do you really know what this person can do, and can you defend the call later? Two intelligence engines and a knowledge graph answer that. The same core powers screening, mobility, and skills work, so a pilot ships in weeks, not quarters, and every evaluation arrives with the evidence behind it.
Programs & agents
The Canvas is where we compose Programs and run agents against the intelligence engines. It is the engine room, not a dashboard your team logs into. Your people stay in the tool they already use, and the agents mirror their evaluations back into your ATS, your HRIS, your pipeline, where the human reads the evidence and makes the call.
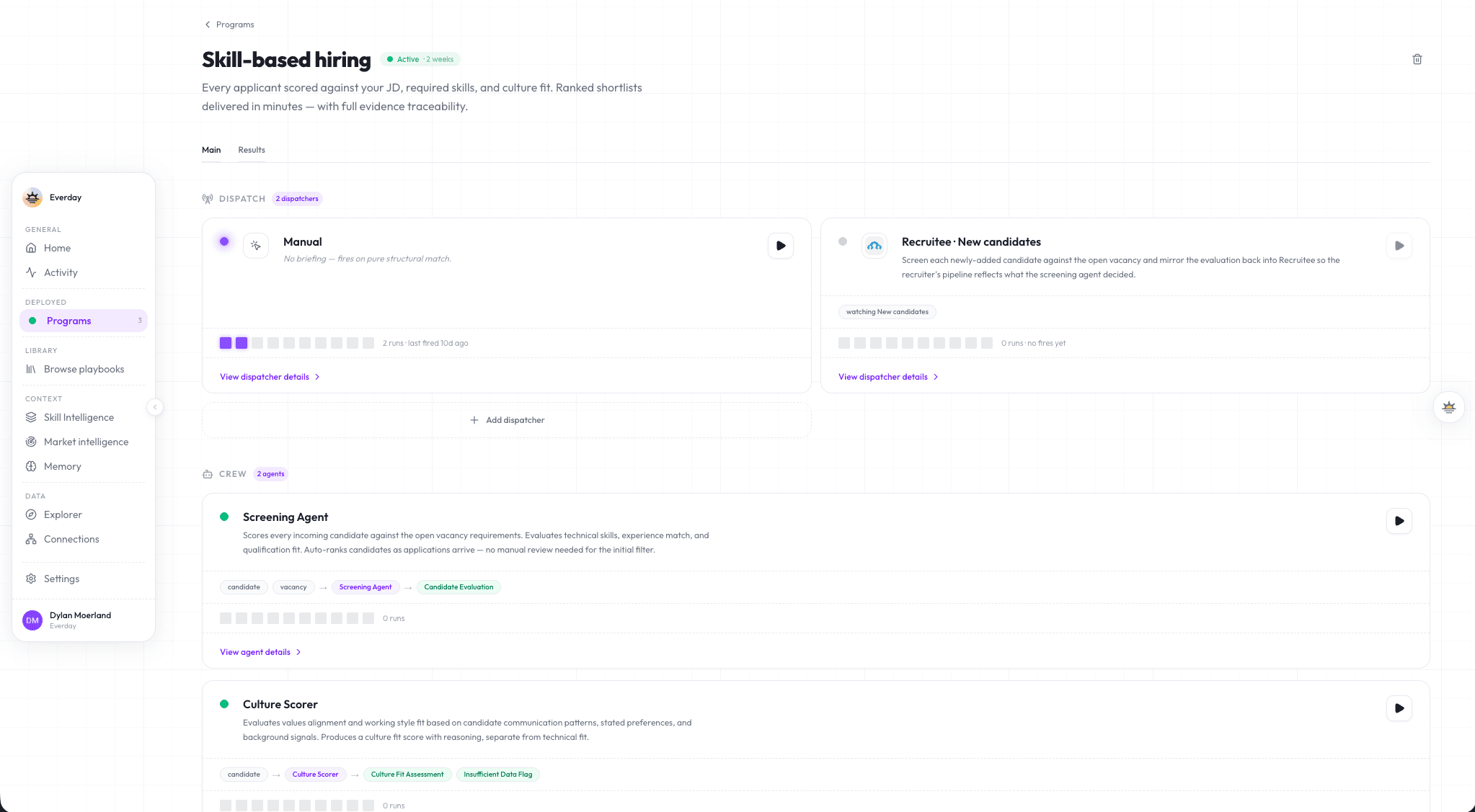
The Canvas
A Skill-based hiring Program on the Canvas. A Screening Agent scores every applicant against the vacancy as applications arrive. A Culture Scorer evaluates values and working-style fit, kept distinct from technical fit.
Agent
Scores every incoming candidate against the open vacancy, technical skills, experience match, qualification fit, and ranks them with the evidence as applications arrive. The recruiter still picks who moves forward.
Agent
Evaluates values and working-style fit against the team profile, kept distinct from the technical evaluation so the two signals stay legible to the person reading them.
Agent
Reads the bench in real time and surfaces the people who fit an open project before it goes to market, so the manager can choose from inside first.
Why you can trust it
When you sit across from a candidate, a manager, or your board, you have to stand behind the call. So the evidence under it has to hold up. Every evaluation is grounded in the intelligence engines, with the full reasoning attached, the way a sharp recruiter defends a shortlist, only at the speed of the inbox. The engine does the legwork. You make the decision.
01
The same candidate against the same vacancy returns the same evaluation. Reasoning is structured, not improvised, so you compare like with like.
02
Every score links back to the evidence, the skills cited, the role data, the conversation excerpts. You can audit any line.
03
Each evaluation comes with the reasoning in plain language, so you can defend your call to a hiring manager or a candidate.
This is the reason you can put an Everday evaluation in front of anyone and stand behind your decision. The engine is built for it from the ground up.
The engines · Engine 01 / 02
Skills Intelligence engine
Most people decisions start from a thin, self-reported picture of skills. Skills Intelligence is the heart of the engine, and it fixes that. It maps skills from real work data, matches them against open roles and projects, and tracks how they develop over time. The same engine powers screening, mobility, and the skill taxonomy a workforce is built on, so every call starts from the truth.
Skill extraction from work data
Reads verified skills from real artifacts, CVs, project history, performance signals, not from a self-rated checklist nobody trusts.
Role and project matching
Scores a person against an open role or project on the skills it actually needs, with the evidence behind each match so the manager can weigh it.
Skill taxonomy, automatic
Builds a current, evidence-based taxonomy from the work people do, so the map matches the territory.
Development paths
Tracks how skills evolve and surfaces the next viable move for a person, internal mobility, reskill, or stretch project.
Ranked shortlist
Senior Backend Engineer
A. de Vries
S. Bakker
M. Janssen
L. Visser
Every score traces to evidence, deterministic, not a guess.
The engines · Engine 02 / 02
Market Intelligence engine
A good call inside the company can still miss what is happening outside it. Market Intelligence grounds your decision in the world beyond your walls, what roles look like across the sector, which skills are scarce, where the supply sits, what compensation clears. Internal skill signal meets external market signal in the same evaluation, so you decide with the full picture.
Role and sector definitions
A live read on what a role actually requires across the sector, not a stale job description from 2019.
Skill supply and scarcity
Which skills are abundant, which are scarce, and where the available people sit, by region, by industry, by seniority.
Compensation signal
Live reference points so a screening evaluation reflects what the market will actually clear at.
Market read
Senior Backend Engineer · NL
Skill supply
Go
ScarceKubernetes
TightPython
AbundantDistributed systems
ScarceComp signal
€72k–€88k
Clears at
€80k
External signal, grounded in the same evaluation, not a static job description.
Agents
Each agent does one job well, screen, match, score, summarize, and reasons over the same intelligence engines. It hands the evidence to the person making the call, never the call itself. What follows feeds back into the graph: who got hired, who moved, what landed, what did not. The engine sharpens with every project.
The agent runs inside a real decision, in the tool your team already uses.
It reasons over Skills and Market Intelligence with the full evidence attached.
A traceable evaluation lands in your existing pipeline, where the human reads it and decides.
The outcome flows back into the graph, so the engine gets sharper for the next decision.
The knowledge graph
People, skills, roles, projects, decisions, and outcomes, held as one graph, cleaned and linked. We carry that structure so it does not have to be reassembled for every question. That is why your evaluations stay consistent, the evidence under each one holds together, and the engine gets sharper with every project you run.
Open by design
No one wants another tool to log into. The Canvas is the engine room, and the work lands where your team already works, ATS, HRIS, ticketing, chat. Connectors are open by design, so your engineering team can extend, audit, or self-host the integration surface.
ATS
Screening evaluations mirrored back into the candidate pipeline. The recruiter reads the evidence and decides, without leaving the tool they already use.
HRIS
Two-way sync against the system of record so skill, role, and mobility signal stay live.
MCP
Expose Programs and engines to your own AI stack through MCP. Audited, scoped, revocable.
API
Run a Program from your own system. Subscribe to outcomes. Pull evidence for an audit trail.
Sharper every project
Every project you run adds evidence to the graph. More evidence sharpens the engines. Sharper engines ground better agents, and a clearer picture under your next decision. The engine you pilot on is the weakest it will ever be.
Start now, and every future call you make rides on a sharper engine.
Questions